ChatGPT Architecture: Will ChatGPT Replace Search Engine?
This article will cover the following topics:
- Introduction Of ChatGPT
- The technical Principles of ChatGPT
- Whether ChatGPT can replace traditional search engines like Google
Introduction Of ChatGPT
As an intelligent dialogue system, ChatGPT has exploded in popularity over the last few days, generating a lot of buzz in the tech community and inspiring many to share ChatGPT-related content and test examples online. The results are impressive. The last time I remember an AI technology causing such a sensation was when GPT-3 was released in the field of NLP, which was over two and a half years ago. Back then, the heyday of artificial intelligence was in full swing, but today it feels like a distant memory. In the multimodal domain, models like DaLL E2 and Stable Diffusion represented the Diffusion Model, which has been popular in the last half year with AIGC models. Today, the torch of AI has been passed to ChatGPT, which undoubtedly belongs to the AIGC category. So, in the current low period of AI after the bubble burst, AIGC is indeed a lifesaver for AI. Of course, we look forward to the soon-to-be-released GPT-4 and hope that OpenAI can continue to support the industry and bring a little warmth.
Let’s not dwell on examples of ChatGPT’s capabilities, as they are everywhere online. Instead, let’s talk about the technology behind ChatGPT and how it achieves such extraordinary results. Since ChatGPT is so powerful, can it replace existing search engines like Google? If so, why? If not, why not?
In this article, I will try to answer these questions from my own understanding. Please note that some of my opinions may be biased and should be taken with a grain of salt. Let’s first look at what ChatGPT has done to achieve such good results.
The Technical Principles of ChatGPT
In terms of overall technology, ChatGPT builds upon the powerful GPT-3.5 large language model (LLM) and introduces “human-annotated data + reinforcement learning” (RLHF) to continuously fine-tune the pre-trained language model. The main goal is to enable the LLM to understand the meaning of human commands (such as writing a short composition, generating answers to knowledge questions, brainstorming different types of questions, etc.) and to judge which answers are high quality for a given prompt (user question) based on multiple criteria (such as being informative, rich in content, helpful to the user, harmless, and free of discriminatory information).
Under the “human-annotated data + reinforcement learning” framework, the training process of ChatGPT can be divided into the following three stages:
ChatGPT: First Stage
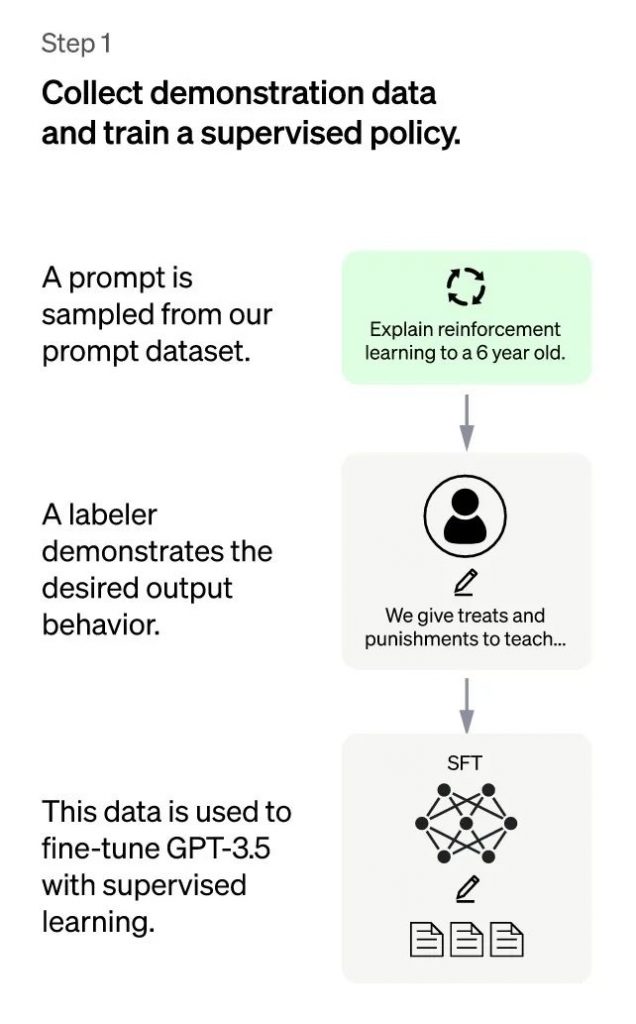
The first stage is a supervised policy model during the cold start phase. Although GPT-3.5 is strong, it is difficult for it to understand the different intentions behind different types of human commands and to judge whether the generated content is of high quality. In order to give GPT-3.5 a preliminary understanding of the intentions behind commands, a batch of prompts (i.e. commands or questions) submitted by test users will be randomly selected and professionally annotated to provide high-quality answers for the specified prompts. These manually annotated <prompt, answer> data will then be used to fine-tune the GPT-3.5 model. Through this process, we can consider that GPT-3.5 has initially acquired the ability to understand the intentions contained in human prompts and to provide relatively high-quality answers based on these intentions. However, it is obvious that this is not enough.
ChatGPT: Second Stage
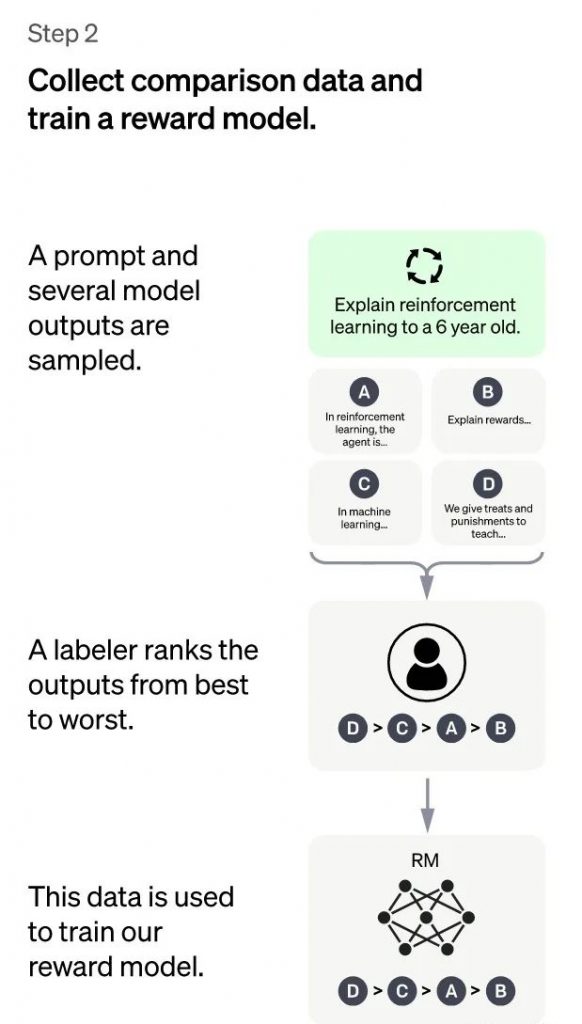
The main goal of the second stage is to train a reward model (RM) using manually annotated training data. This stage involves randomly sampling a batch of user-submitted prompts (which are mostly the same as those in the first stage), using the cold-start model fine-tuned in the first stage to generate K different answers for each prompt. As a result, the model produces the data <prompt,answer1>,<prompt,answer2>,….<prompt,answerK>. Then, the annotator sorts the K results according to multiple criteria (such as relevance, informativeness, harmfulness, etc.) and gives the ranking order of the K results, which is the manually annotated data for this stage.
Next, we are going to use the sorted data to train a reward model using the common pair-wise learning to rank method. For K sorted results, we combine them two by two to form $\binom{k}{2}$ training data pairs. ChatGPT uses a pair-wise loss to train the Reward Model. The RM model accepts an input of <prompt, answer> and outputs a score that evaluates the quality of the answer. For a training data pair <answer1, answer2>, we assume that answer1 comes before answer2 in the manual sorting, so the loss function encourages the RM model to score <prompt, answer1> higher than <prompt, answer2>.
In summary, in this phase, the supervised policy model generates K results for each prompt after cold start. The results are manually sorted in descending order of quality, and used as training data to train the reward model using the pair-wise learning to rank method. For the trained RM model, the input is <prompt, answer>, and the output is the quality score of the result. The higher the score, the higher the quality of the generated response.
ChatGPT: Third Stage
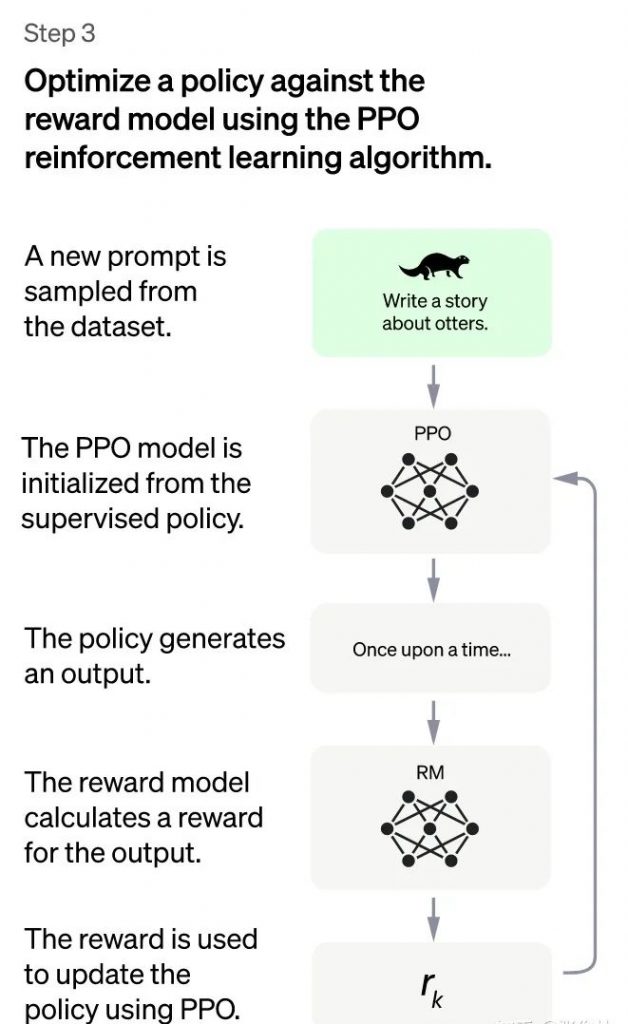
In the third phase of ChatGPT, reinforcement learning is used to enhance the ability of the pre-trained model. In this phase, no manual annotation data is needed, but the RM model trained in the previous phase is used to update the parameters of the pre-trained model based on the RM scoring results. Specifically, a batch of new commands is randomly sampled from the user-submitted prompts (which are different from those in the first and second phases), and the parameters of the PPO model are initialized by the cold start model. Then, for the randomly selected prompts, the PPO model generates answers, and the RM model trained in the previous phase provides a reward score for the quality evaluation of the answers. This reward score is the overall reward given by the RM to the entire answer (consisting of a sequence of words). With the final reward of the sequence of words, each word can be regarded as a time step, and the reward is transmitted from back to front, generating a policy gradient that can update the PPO model parameters. This is the standard reinforcement learning process, which aims to train the LLM to produce high-reward answers that meet the RM standards, that is, high-quality responses.
If we continue to repeat the second and third phases, it is obvious that each iteration will make the LLM model more and more capable. Because the second phase enhances the ability of the RM model through manual annotated data, and in the third phase, the enhanced RM model will score the answers to the new prompts more accurately, and use reinforcement learning to encourage the LLM model to learn new high-quality content, which plays a role similar to using pseudo-labels to expand high-quality training data, so the LLM model is further enhanced. Obviously, the second phase and the third phase have a mutual promotion effect, which is why continuous iteration will have a sustained enhancement effect.
Despite this, I don’t think that using reinforcement learning in the third phase is the main reason why the ChatGPT model performs particularly well. Suppose that in the third phase, reinforcement learning is not used, but the following method is used instead: similar to the second phase, for a new prompt, the cold start model can generate k answers, which are scored by the RM model respectively, and we choose the answer with the highest score to form a new training data <prompt, answer> to fine-tune the LLM model. Assuming that this mode is used, I believe that its effect may be comparable to reinforcement learning, although it is not as sophisticated, but the effect may not necessarily be much worse. No matter what technical mode is adopted in the third phase, it is essentially likely to use the RM learned in the second phase to expand the high-quality training data of the LLM model.
The above is the training process of ChatGPT, which is mainly based on the paper of instructGPT. ChatGPT is an improved instructGPT, and the improvement points are mainly different in the method of collecting annotated data. In other aspects, including the model structure and training process, it basically follows instructGPT. It is foreseeable that this Reinforcement Learning from Human Feedback technology will quickly spread to other content generation directions, such as a very easy to think of, similar to “A machine translation model based on Reinforcement Learning from Human Feedback” and many others. However, personally, I think that adopting this technology in a specific content generation field of NLP may not be very meaningful anymore, because ChatGPT itself can handle a wide variety of tasks, covering many subfields of NLP generation, so if a subfield of NLP adopts this technology again, it actually does not have much value, because its feasibility is considered to have been verified by ChatGPT. If this technology is applied to other modal generation fields such as images, audio, and video, it may be a more worthy direction to explore, and perhaps soon we will see similar work such as “A XXX diffusion model based on Reinforcement Learning from Human Feedback”, which should still be very meaningful.
The third phase of the ChatGPT training process is to use reinforcement learning to enhance the ability of the pre-trained model. In this phase, no human-labeled data is required, but rather the RM model trained in the previous phase is used to update the pre-trained model parameters based on its scoring results. Specifically, a batch of new commands (i.e. prompts that are different from those used in phases 1 and 2) is randomly sampled from the user-submitted prompts, and the cold start model is used to initialize the PPO model parameters. Then, for the randomly sampled prompts, the PPO model is used to generate answers, and the RM model trained in the previous phase is used to provide a reward score for the quality of the answers. This reward score is the overall reward given to the entire answer (consisting of a sequence of words) by the RM model. With the final reward of the word sequence, each word can be viewed as a time step, and the reward is passed back from the end to the beginning, generating a policy gradient that can update the PPO model parameters. This is a standard reinforcement learning process, with the aim of training the LLM to produce high-reward answers, i.e. high-quality answers that meet the RM standards.
Whether ChatGPT Can Replace Traditional Search Engines Like Google
Given that it seems like ChatGPT can almost answer any kind of prompt, it’s natural to wonder: Can ChatGPT or a future version like GPT4 replace traditional search engines like Google? I personally think that it’s not possible at the moment, but with some technical modifications, it might be possible in theory to replace traditional search engines.
There are three main reasons why the current form of chatGPT cannot replace search engines: First, for many types of knowledge-related questions, chatGPT will provide answers that appear to be reasonable but are actually incorrect. ChatGPT’s answers seem well thought out and people like me, who are not well-educated, would believe them easily. However, considering that it can answer many questions well, this would be confusing for users: if I don’t know the correct answer to the question I asked, should I trust the result of ChatGPT or not? At this point, you cannot make a judgment. This problem may be fatal.
Secondly, the current model of ChatGPT, which is based on a large GPT model and further trained with annotated data, is not friendly to the absorption of new knowledge by LLM models. New knowledge is constantly emerging, and it is unrealistic to re-train the GPT model every time a new piece of knowledge appears, whether in terms of training time or cost. If we adopt a Fine-tune mode for new knowledge, it seems feasible and relatively low-cost, but it is easy to introduce new data and cause disaster forgetting of the original knowledge, especially for short-term frequent fine-tuning, which will make this problem more serious. Therefore, how to almost real-timely integrate new knowledge into LLM is a very challenging problem.
Thirdly, the training cost and online inference cost of ChatGPT or GPT4 are too high, resulting in if facing real search engine’s millions of user requests, assuming the continuation of the free strategy, OpenAI cannot bear it, but if the charging strategy is adopted, it will greatly reduce the user base, whether to charge is a dilemma, of course, if the training cost can be greatly reduced, then the dilemma can be self-solved. The above three reasons have led to ChatGPT not being able to replace traditional search engines at present.
Can these problems be solved? Actually, if we take the technical route of ChatGPT as the main framework and absorb some of the existing technical means used by other dialogue systems, we can modify ChatGPT from a technical perspective. Except for the cost issue, the first two technical issues mentioned above can be solved well. We just need to introduce the following abilities of the sparrow system into the ChatGPT: evidence display of the generated results based on the retrieval results, and the adoption of the retrieval mode for new knowledge introduced by the LaMDA system. Then, the timely introduction of new knowledge and the credibility verification of generated content are not major problems.